

One of the things I’m most proud of creating at the ODI is the Data Spectrum, to us help understand the language of data.
When ODI launched in 2012, there was a lot of uninformed rhetoric about data. Ministers would talk on-stage about the revolution in “big, open, personal data”, mixing categories and leaving audiences at best confused, at worst deeply concerned about their personal data. We tried immediately to combat this with a graphic that separated those ideas and provoke questions about their intersection.
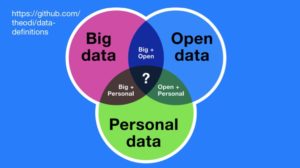
But this wasn’t good enough.
It took many hundreds of presentations, trying repeatedly to reset the conversation before we arrived at something that did (perhaps my background in astrophysics led me to use the word ‘spectrum’).
The Data Spectrum reframes the discussion about one simple question — “can I use the data?”
In a practical sense, the answer to this question is about legal permission: do I have a license to use the data?
This is then irrespective of whether the data is ‘big, medium or small’ or ‘personal, commercial or government’.
With Open Data, this is [relatively] easy. Open Data is that anyone can use for any purpose for free: there are a range of open licenses that can be applied to ensure this (e.g. Creative Commons, Open Government Licence)
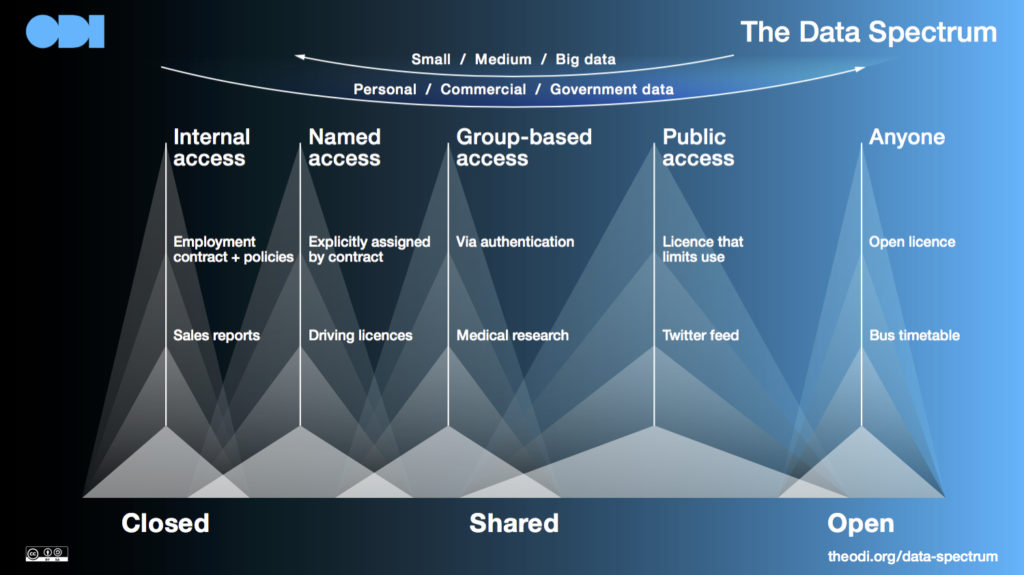
While at the ODI, for Shared Data and Closed Data we gave examples, but we did not focus on trying to ‘solve’ for those categories as this was outside its remit.
Having reflected on this now for some years, I think there is potential to define Shared in a more concrete way—that is enabling to the web of data at-scale.
Shared data is, largely, held in the private sector. The users are also, mostly, in the private sector.
The collective action challenge is that data licensing is typically done on a point-to-point basis, is often complex and between just two parties (that can also represent a cascade of third-party rights).
There are a number of ‘data as a service’ companies who provide blanket licensing, but these tend to be very high-level and become custom deals at the point of either scale or complexity.
We’ve attempted (and failed) to implement rights management schemes in the past (e.g. DRM in the music industry) and have been making some progress on machine-readable descriptions of rights since — the W3C adopted the Open Digital Rights Language in 2018, but such schemes have been slow in adoption. We’ve also seen huge progress on the technical development of the semantic web and schema.org but we’ve not, yet, translated this into ways non-technical people can engage with, especially around their corporate data.
Data increases in value the more it is connected
To increase these connections we must catalyse data sharing. We also need to protect people, confidentiality, intellectual property and security.
We need good use cases that change the culture of closed that permeates our current thinking that can illustrate the benefits. Sir Jeremey Heywood (former head of the UK civil service) believed that this was fundamental to the future.
I hope that Icebreaker One is one such catalyst — we won’t fix our climate emergency without more sharing of public and private data.
Creative Commons defined a step-change in thinking. It enabled us all to say, for example “it’s okay to use this image for free”, in advance. As of May 2018, there were an estimated 1.4 billion works licensed using a CC licence.
Another interesting example is the UK Open Banking Standard, which pre-emptively defines and mandates ways to share personal data, it is now regulated and every UK high street bank has engage.
We need to make it easier for organisations to pre-emptively licence non-open data: for both public and private good. Can we, for example, say “for this use-case, this organisation can access and use information for a fee” and have a different licence for a different set of users?
So, why don’t we define Shared Data on the Data Spectrum as data that has a pre-emptive licence? (Closed Data is then data that requires a per-use, custom licence).
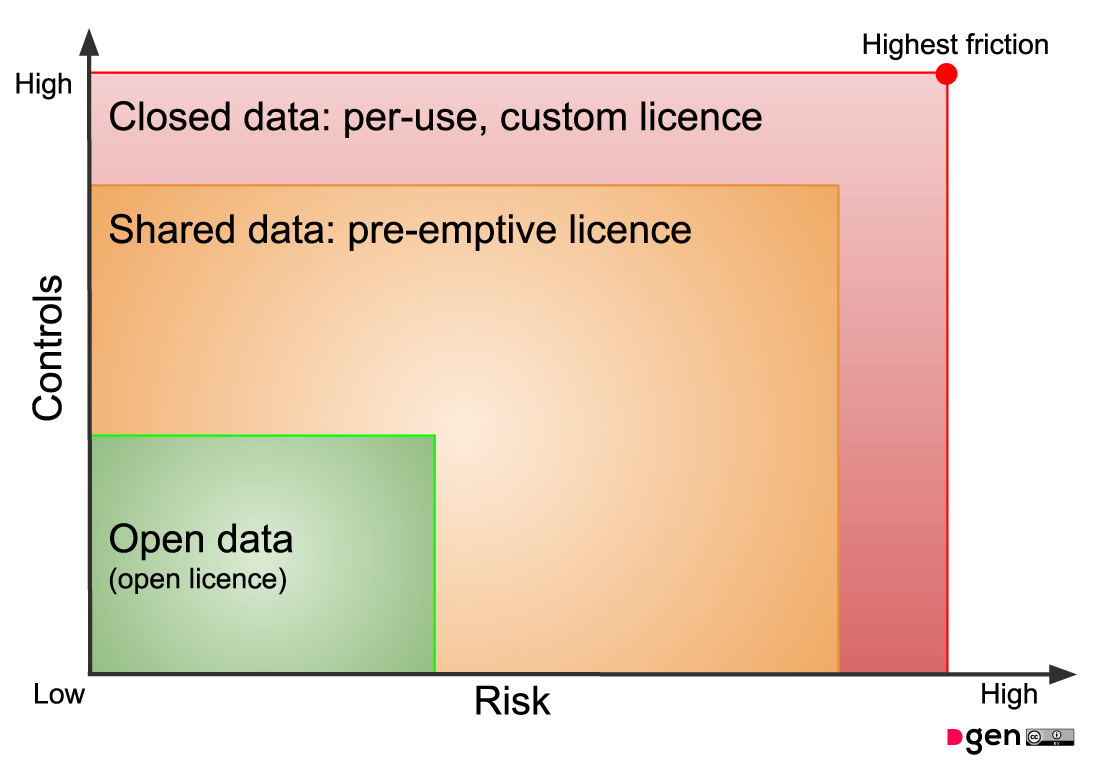
To do this, we must have clear, Open Data descriptions of the Shared Data that exists and how it might be used (how it is licensed).
Publishing open data that describes the shared data will enable search engines (and therefore you) to find it. If the licensing is clear, then the friction between discovery and usage is reduced.
Doing so will increase the size of the observable dataverse and help to unlock innovation while protecting the interests of individuals, organisations and countries to use it for both public and private good.
To summarise:
Open data: data that anyone can use, for any purpose, for free
Shared data: data that has pre-emptive licences for specific use-cases, and open data descriptions of both the data and the licence conditions
Closed data: data that requires a per-use, custom licence, negotiated on a case-by-case basis


